Tempo aproximado para leitura: 00:05:00 min
Dúvida
Quais são as parametrizações básicas da base de dados RM para o SQL Server?
Ambiente
Framework - Framework (Linha RM) - Banco de Dados - A partir da versão 12.1.18
Solução
Estas recomendações são apenas um direcionamento básico para uma boa operação do servidor de banco de dados e não deve ser considerado como único padrão de avaliação, monitoração, e configuração do banco de dados que deve ser realizado por o DBA responsável.
1 - COLLATION
- No padrão CorporeRM o Collation deverá ser definido com SQL_Latin1_General_CP1_CI_AI, e a linguagem, Default Language como US_ENGLISH ou ENGLISH para os logins RM e SYSDBA.
-
Seguindo o padrão da TOTVS, na criação do banco Corpore deve-se utilizar o sort order 54, DICTIONARY ORDER, CASE-INSENSITIVE, ACCENT-INSENSITIVE, FOR USE WHITH 1252 CHARACTER SET lembramos que na instalação o default é o sort order 52. Para confirmar, realize a consulta:
sp_helpsort
Lembrando que os logins RM e SYSDBA deveram ser criados, conforme script de Acerta Usuários: Framework - Framework RM - BD - Acerta usuário SQL
2 - SERVER AUTHENTICATION
Verifique a autenticação que está sendo realizada para conexão do SQL.

Para isso, basta clicar com o botão direito no nome do servidor Management Studio e clicar em propriedades.
Na guia Security, na opção Server authentication, marque a opção SQL Server and Windows Authentication mode. A base de dados RM utiliza o usuário do banco de dados para realizar a autenticação do sistema, por este motivo, precisamos da autenticação do SQL para acessar o sistema. Verifique se o serviço vai reiniciar após confirmar esta opção.
3 - PARÂMETROS
Partindo do pressuposto que a base vazia foi criada com o nome de Base_RM e o script de usuários também já foi executado na mesma, vamos conferir alguns parâmetros do banco:
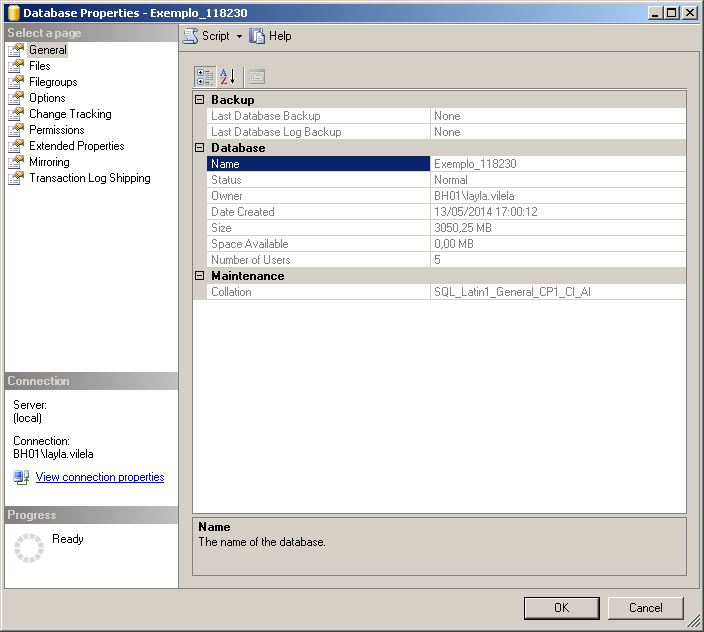
Selecione o menu propriedades da base RM, nesse menu estarão disponíveis todas as informações gerais da base de dados:
- General - Esta guia contém informações gerais da base, como data de criação, nome, tamanho, último backup, etc.
- Files - Contém os Databases files (a localização do arquivo mdf e ldf que contém os dados e o tamanho dos mesmos) onde podemos criar arquivos secundários apontando discos diferentes, que assim que esgotar o espaço do primeiro arquivo irá dar continuidade ao próximo.
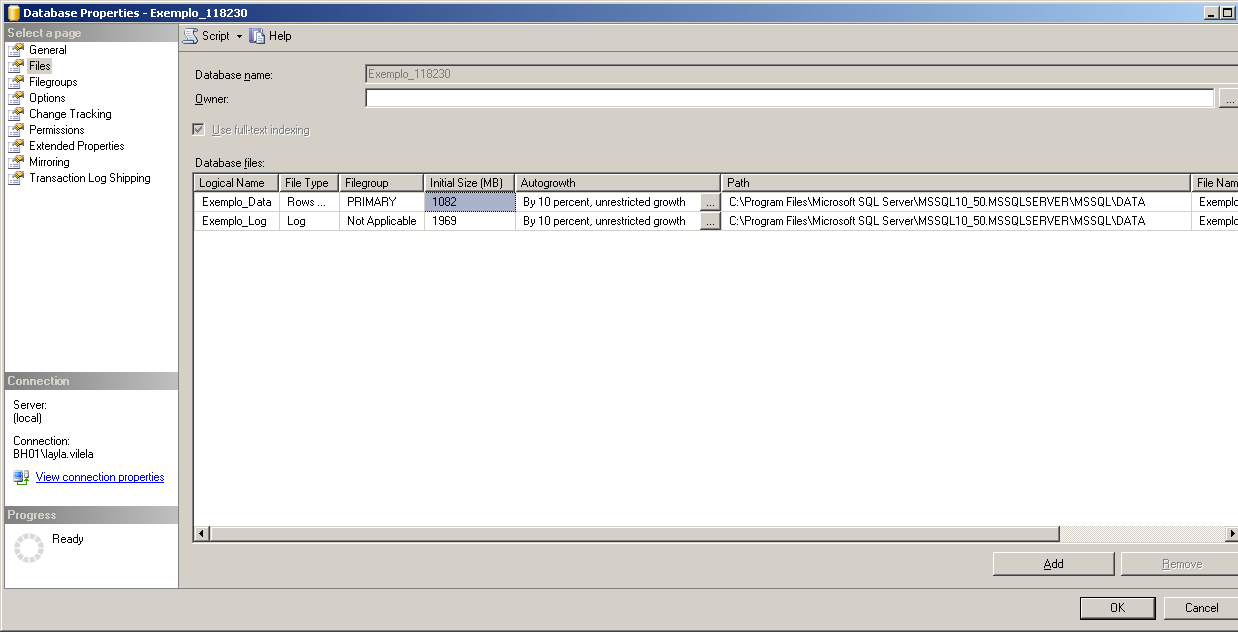
Sugerimos que seja parametrizado para o crescimento automático Enable Autogrowth e no File Growth utilizar o In Percent igual a 10, já no Maximum File Size devemos ter muito critério ao marcar a opção de Unrestrict File Growth, apesar de recomendarmos, pois enquanto tiver espaço em disco e o banco necessitar ele irá expandir sem problemas, porém se o espaço estourar poderá danificar o banco de dados:

-
Base.ldf - Contém o nome do file name, a localização do arquivo ldf que contém o log, e o tamanho do mesmo. Quanto à configuração, podemos nos basear nas configurações acima.
-
Filegroupes – Os grupos de arquivos permitem que os arquivos de banco de dados e objetos sejam logicamente agrupados.
- Options – Solicitamos que marque somente o parâmetro:
- ANSI NULL Default – Quando esta opção é setada, os tipos de dados ou colunas que não estão explicitamente definidas como NOT NULL durante a criação ou alteração da tabela irá permitir valores nulos.
Verificando os demais parâmetros:
-
Auto Close – Quando esta opção está marcada, o banco criará overhead adicional associado com abertura e fechamento de arquivos do banco de dados, o que não recomendamos para bancos que estão constantemente em utilização.
- Auto Update Statistics – Configurada como True, as estatísticas de índice são automaticamente atualizadas, podendo gerar queda de performance.
-
Auto Create Statistics – Configurada como True, as estatísticas de índice são automaticamente criadas, sempre que você criar um índice, o SQL Server cria um conjunto de estatísticas sobre os dados contidos dentro do índice. O otimizador de consulta utiliza essas estatísticas para determinar se ele deve ou não utilizar o índice para ajudar a processar a consulta. Devido a característica das aplicações da linha RM, pode ser benéfico para o desempenho de relatórios e outros itens customizados que eventualmente demandem filtros específicos que não são compreendidos por índices padrões do produto, bem como em melhorias de planos de execução ineficientes. Por padrão o backup de nossa base vazia, utilizada normalmente para implantação possui este parâmetro desmarcado para não gerar estatísticas em todas as tabelas. No entanto, esta é uma opção do banco de dados que poderá ser utilizada em cenários específicos de análise de desempenho mensurando o impacto, custo de manutenção e resultados obtidos com a utilização deste parâmetro como TRUE. A Microsoft recomenda a utilização deste parâmetro como TRUE por default.
-
Auto Shrink – Caso esta opção esteja setada o banco, os arquivos de log encolhem-se automaticamente, reduzindo o espaço de disco rígido e isso pode degradar o desempenho, caso seja necessário encolher o banco, você poderá utilizar o comando DBCC SHRINKDATABAS.
-
Quoted Identifiers – Marcando esta opção, os nomes de objetos dentro de aspas duplas não precisam obedecer à convecção para atribuição de nomes reservados ao SQL, como "date", "primary", sugerimos a não marcação deste parâmetro.
-
Recursive Trigger – Se não for adequadamente implementada, a recursão pode levar a loop sem fim.
-
Torn Page Detection – Este parâmetro marcado detecta se uma página está danificada, listando no event view, fica a critério do cliente marcar ou não esta opção, pois não influenciará no desempenho do banco.
- Compatibility Level – Vide artigo: RM - BD - Nível de Compatibilidade
4 - MANUTENÇÃO
Verifique o artigo sobre a manutenção do SQL Server: RM - BD - Manutenção rotineira no SGBD SQL Server
5 - RECOVERY MODEL/IMPORTÂNCIA DA VERIFICAÇÃO DA INTEGRIDADE DA BASE DE DADOS
O log do SQL Server poderá crescer mais ou menos a depender do recovery model escolhido, dessa forma, verifique nossas orientações sobre a verificação de integridade da base de dados: Framework - Framework RM - BD - Importância da verificação da integridade da base de dados
0 Comentários